// Method
Three Axes of Analysis
From the Shapley matrix Φ, capturing each input feature's contribution to each generated token, we derive three complementary metrics.
🌐
Global SHAP
Aggregates contributions across all features and tokens to quantify overall audio vs. visual balance.
\( \begin{align} \text{A-SHAP} &= \frac{\displaystyle\sum_{j \in \mathcal{A}} \sum_{t=1}^{T} |\phi_{j,t}|}{\displaystyle\sum_{j \in \mathcal{F}} \sum_{t=1}^{T} |\phi_{j,t}|} \\
\text{V-SHAP} &= \frac{\displaystyle\sum_{j \in \mathcal{V}} \sum_{t=1}^{T} |\phi_{j,t}|}{\displaystyle\sum_{j \in \mathcal{F}} \sum_{t=1}^{T} |\phi_{j,t}|}\end{align} \)
📈
Generative SHAP
Tracks how modality reliance evolves across windowed stages of autoregressive decoding.
\( \begin{align}
\text{A-SHAP}^{(w)} &= \frac{\displaystyle\sum_{j \in \mathcal{A}} \sum_{t \in \mathcal{T}_w} |\phi_{j,t}|}{\displaystyle\sum_{j \in \mathcal{F}} \sum_{t \in \mathcal{T}_w} |\phi_{j,t}|}, \label{eq:gen_ashap} \\
\text{V-SHAP}^{(w)} &= 1 - \text{A-SHAP}^{(w)}. \label{eq:gen_vshap}
\end{align} \)
🔗
Alignment SHAP
Examines temporal correspondence between input feature positions and output token positions.
\( H_{k,w}^{(m)} = \frac{\displaystyle\sum_{j \in \mathcal{F}_k^{(m)}} \sum_{t \in \mathcal{T}_w} |\phi_{j,t}|}{\displaystyle\sum_{w'=1}^{W} \sum_{j \in \mathcal{F}_k^{(m)}} \sum_{t \in \mathcal{T}_{w'}} |\phi_{j,t}|} \)
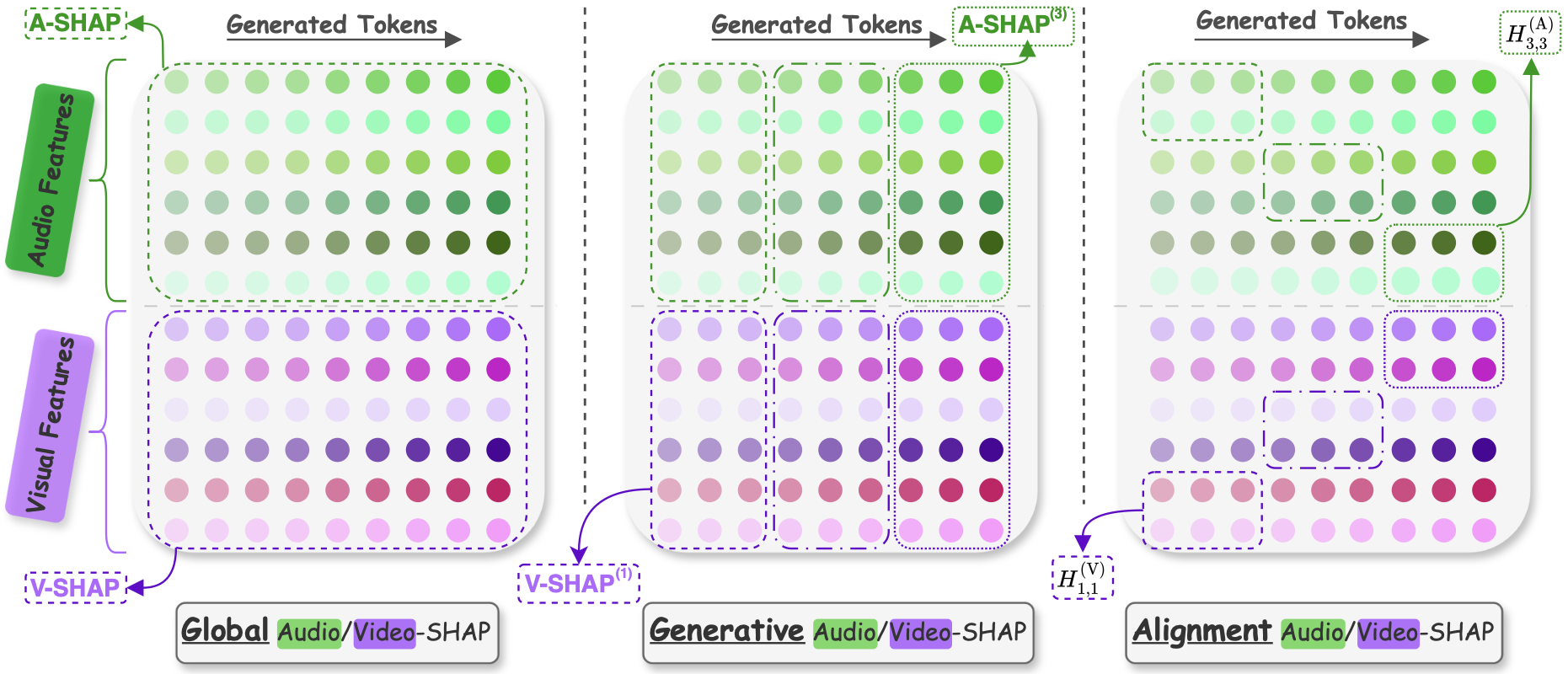
Overview of the three proposed SHAP-based analyses. From the Shapley matrix Φ, we compute: Global SHAP (overall modality balance), Generative SHAP (contribution dynamics across decoding), and Temporal Alignment SHAP (input-output correspondence).