I'm Umberto Cappellazzo, and I work as a Gen AI Research Engineer at NatWest Group, London, UK, in the CAIRO group led by Maja Pantic. My manager is Stavros Petridis. Previously I was a Reseaarch Associate at Imperial College London. I've been working on self-supervised audio representation learning, speech tokenizers, and multimodal LLMs. In particular, I've mainly focused on advancing audio-visual speech recognition through Large Language Models, in close collaboration with Meta AI. I've published several papers along this direction (IEEE ICASSP x3, Interspeech x3, IEEE ASRU, NeurIPS). Previously, I obtained my PhD in Information Engineering and Computer Science from the University of Trento, Italy.
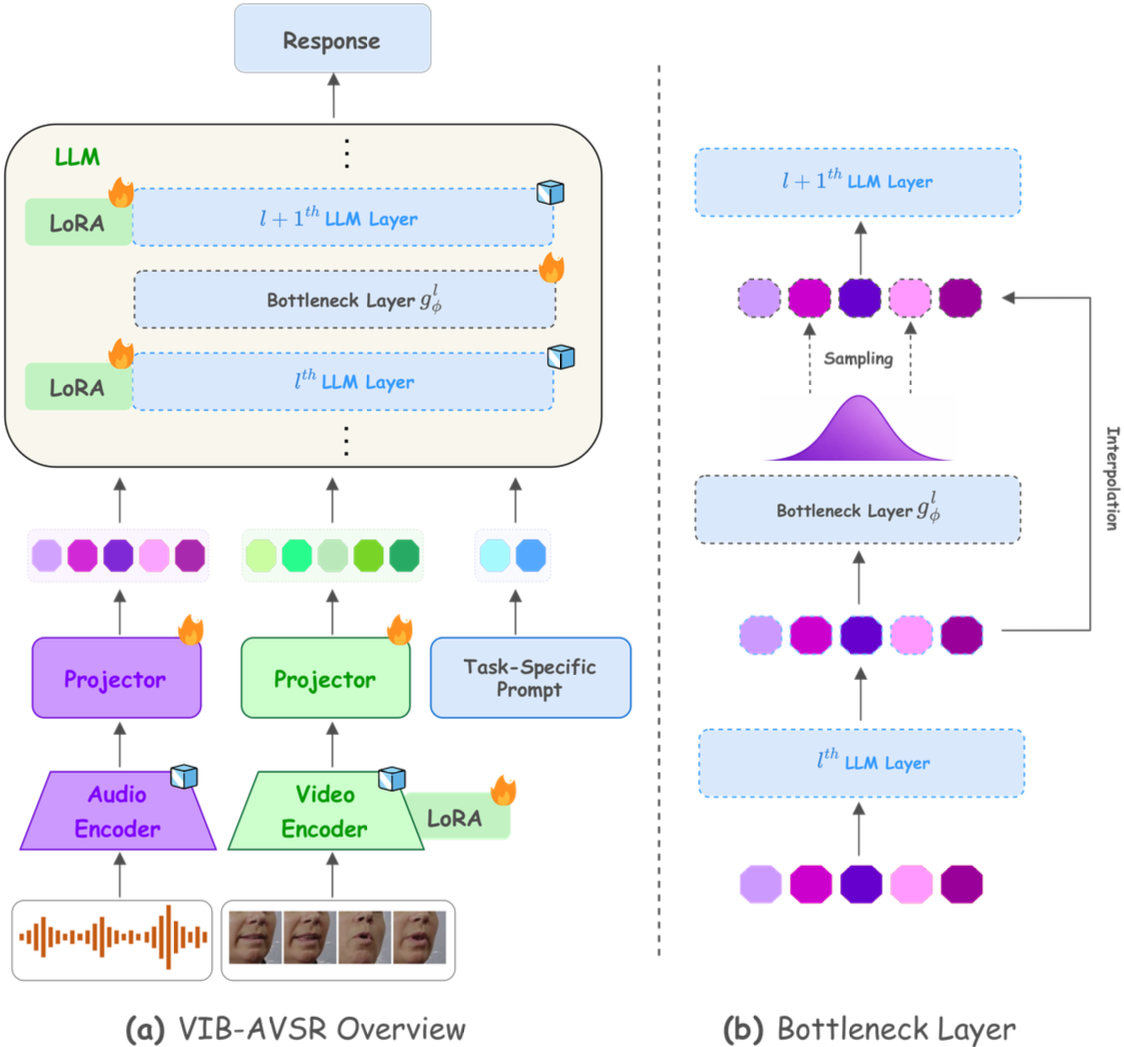
LLM-based AVSR that reads lips and listens at once — state-of-the-art on LRS2/LRS3 via modality-aware compression and LoRA.
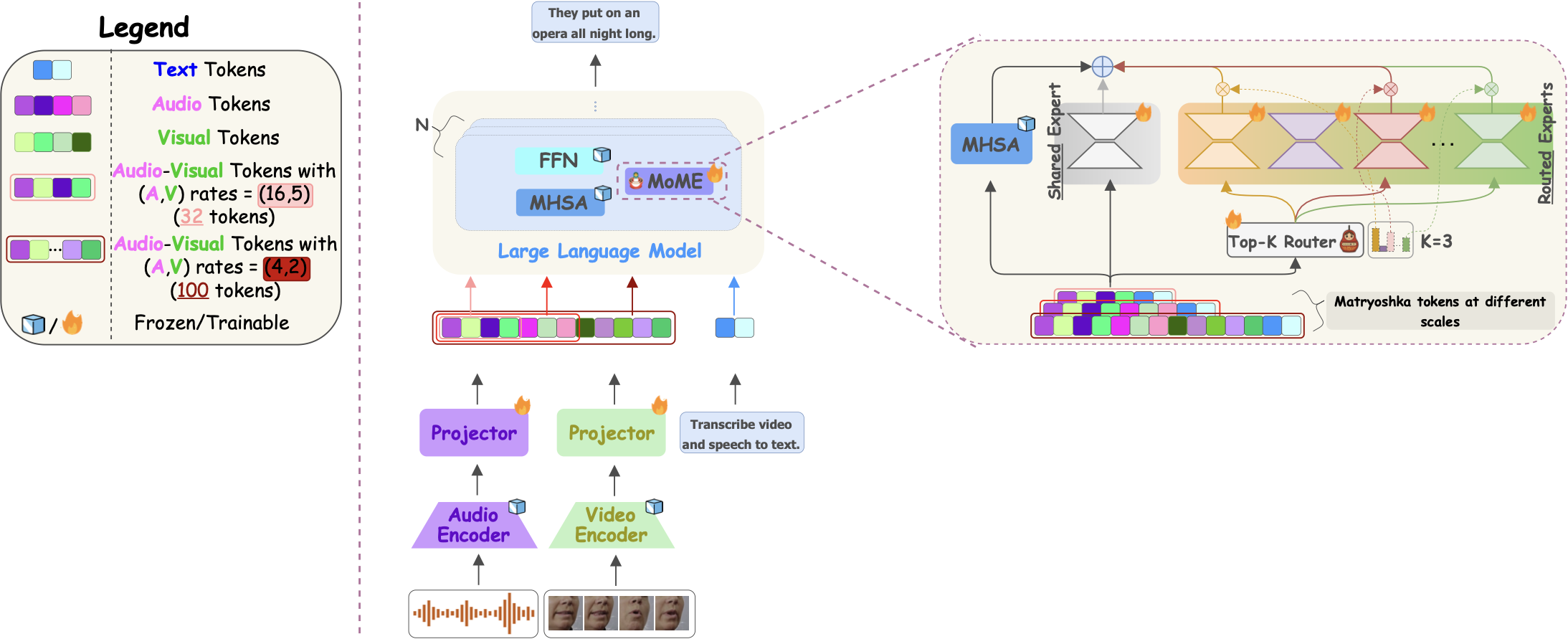
One model, many granularities. Matryoshka representation learning and Mixture-of-Experts for adaptive inference.
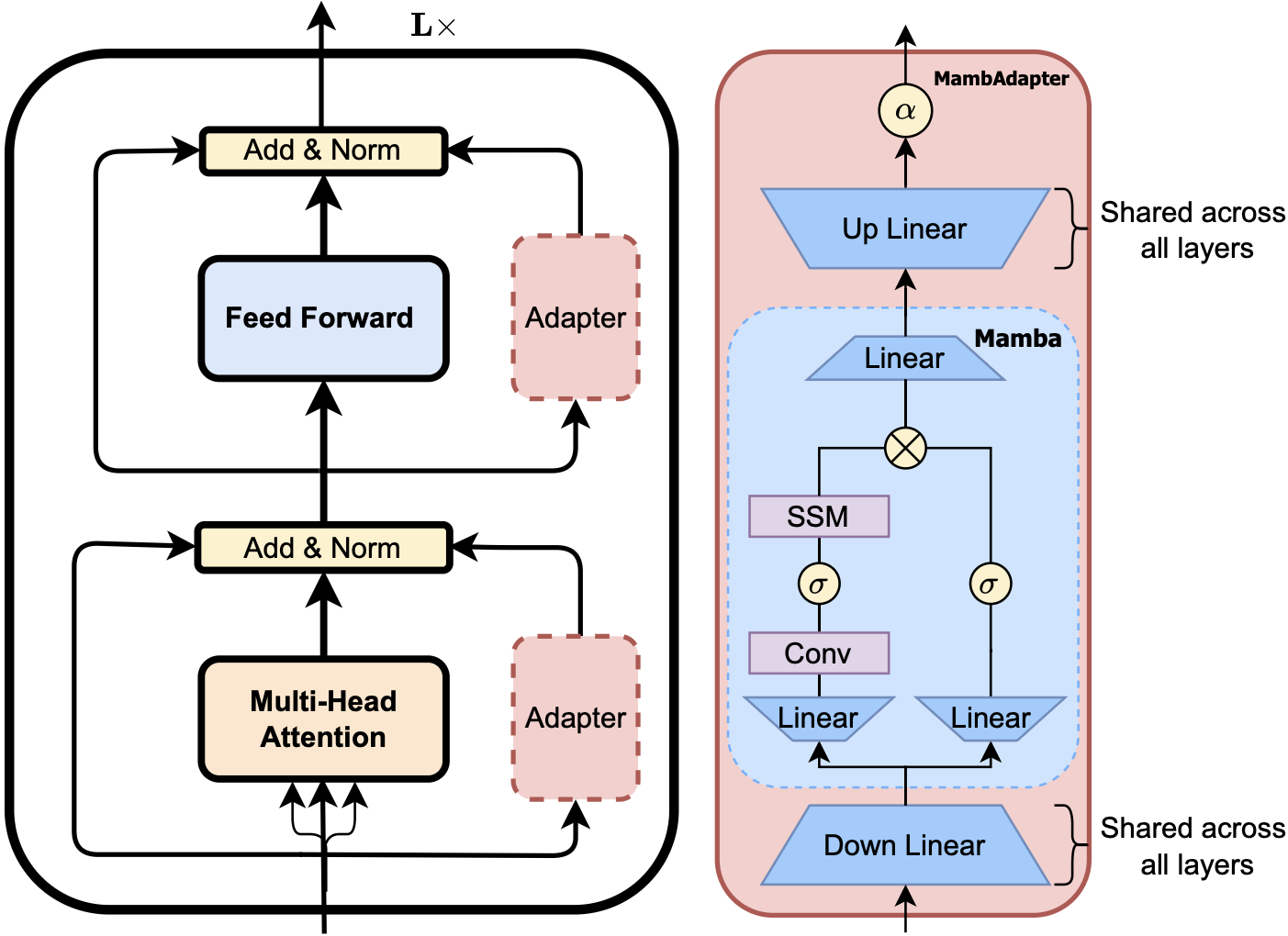
Adapters, LoRA, prompt-tuning, and soft Mixture-of-Adapters — matching full fine-tuning at a fraction of the cost.
Large-scale self-supervised audio pre-training via next-embedding auto-regressive objectives in latent space.
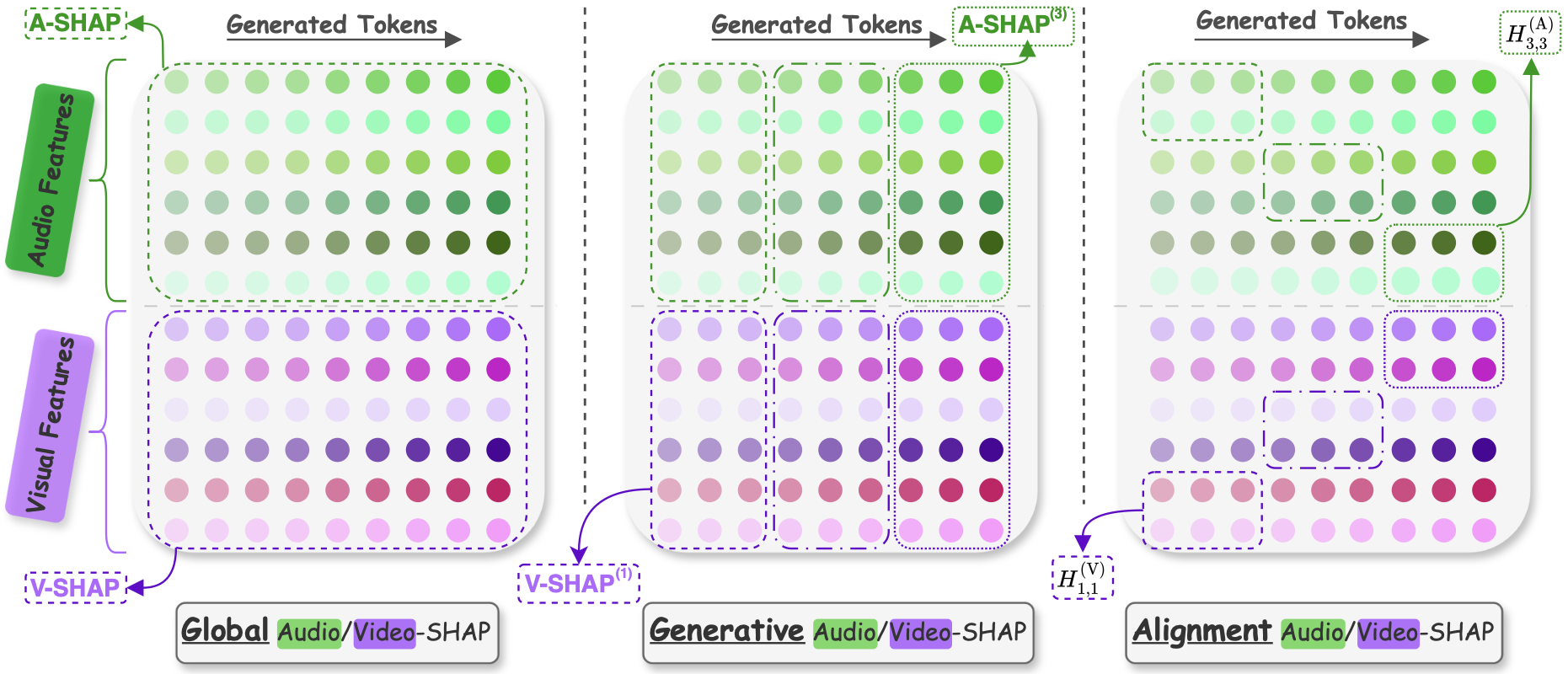
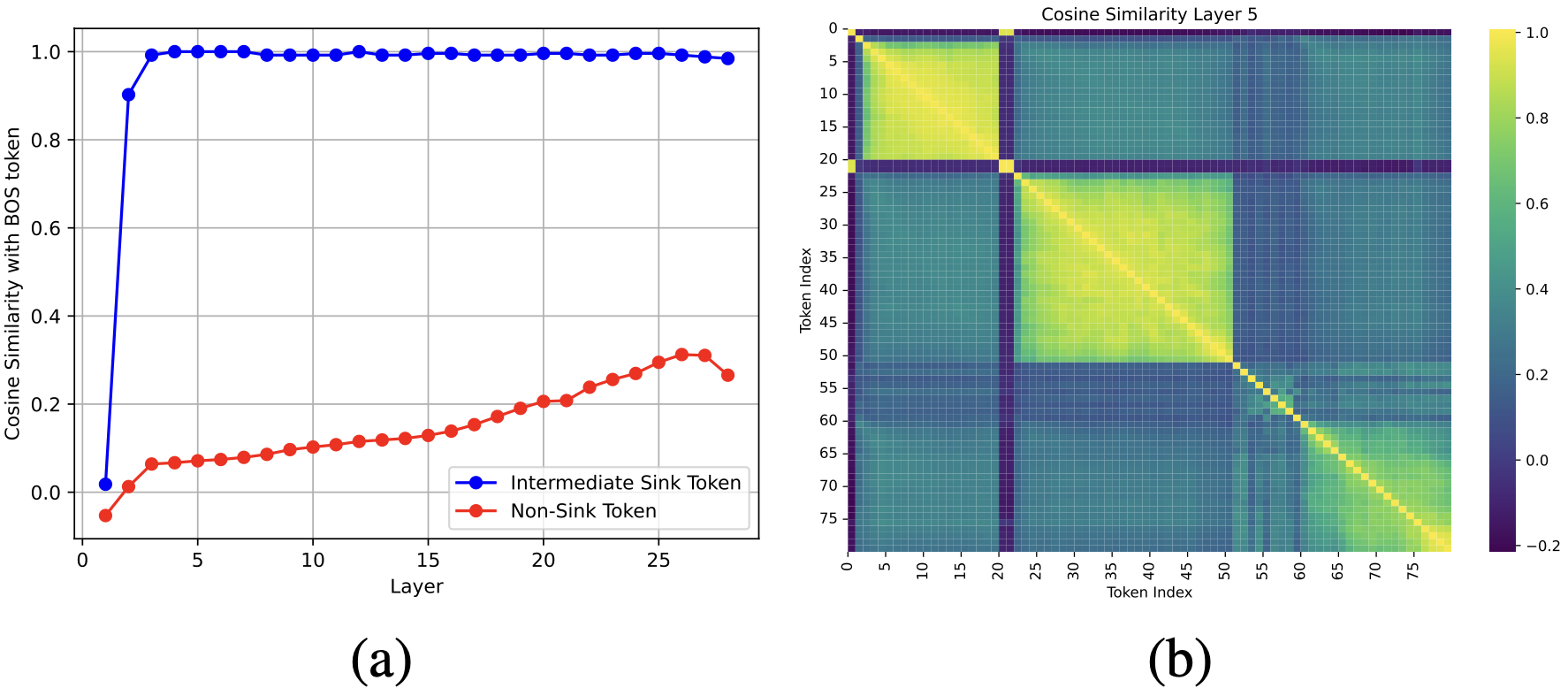
Probing attention sinks, massive activations, and modality contributions via Shapley attribution.
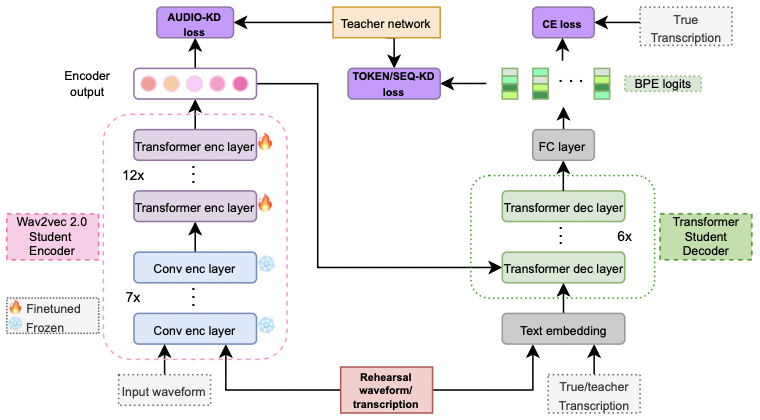
Learning sequentially without forgetting — rehearsal, distillation, and contrastive objectives for spoken language understanding (SLU).
Advised by Stavros Petridis in the group led by Maja Pantic. Focus on multimodal LLMs and self-supervised audio representation learning.
Nine-month visit with iBUG exploring LLMs for AVSR, advised by Stavros Petridis — the work behind Llama-AVSR.
Finite-state methods with modern neural architectures group; early-exit techniques for CTC/MMI.
"Efficient Knowledge Transfer and Adaptation for Speech and Beyond." Defended cum laude, Jan 2025. Supervised by Daniele Falavigna and Alessio Brutti.
Thesis: deep-learning-based ECG delineator. Supervised by Michele Rossi and Matteo Gadaleta.
Thesis: message authentication over an ideal or noisy channel. Supervised by Nicola Laurenti.
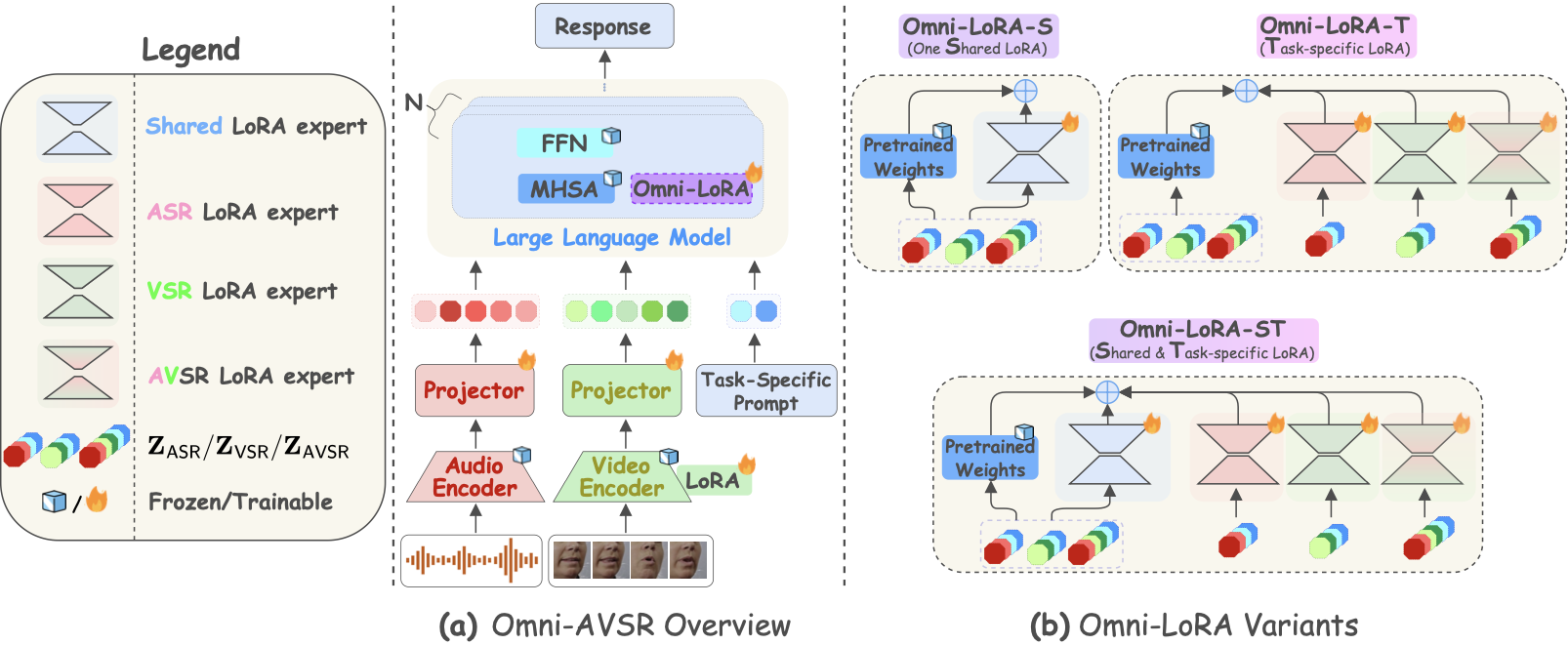
U. Cappellazzo, M. Kim, P. Ma, H. Chen, X. Liu, S. Petridis, M. Pantic
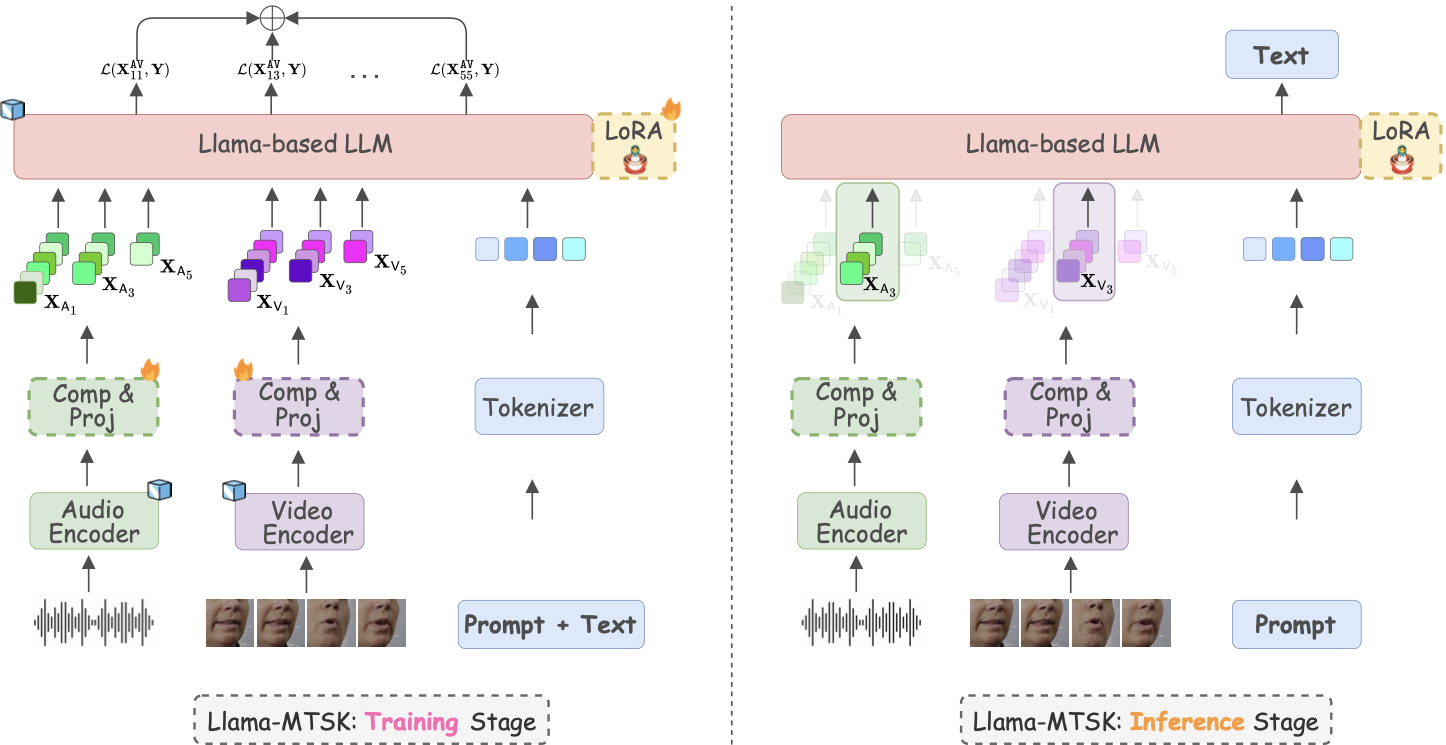
U. Cappellazzo, M. Kim, S. Petridis
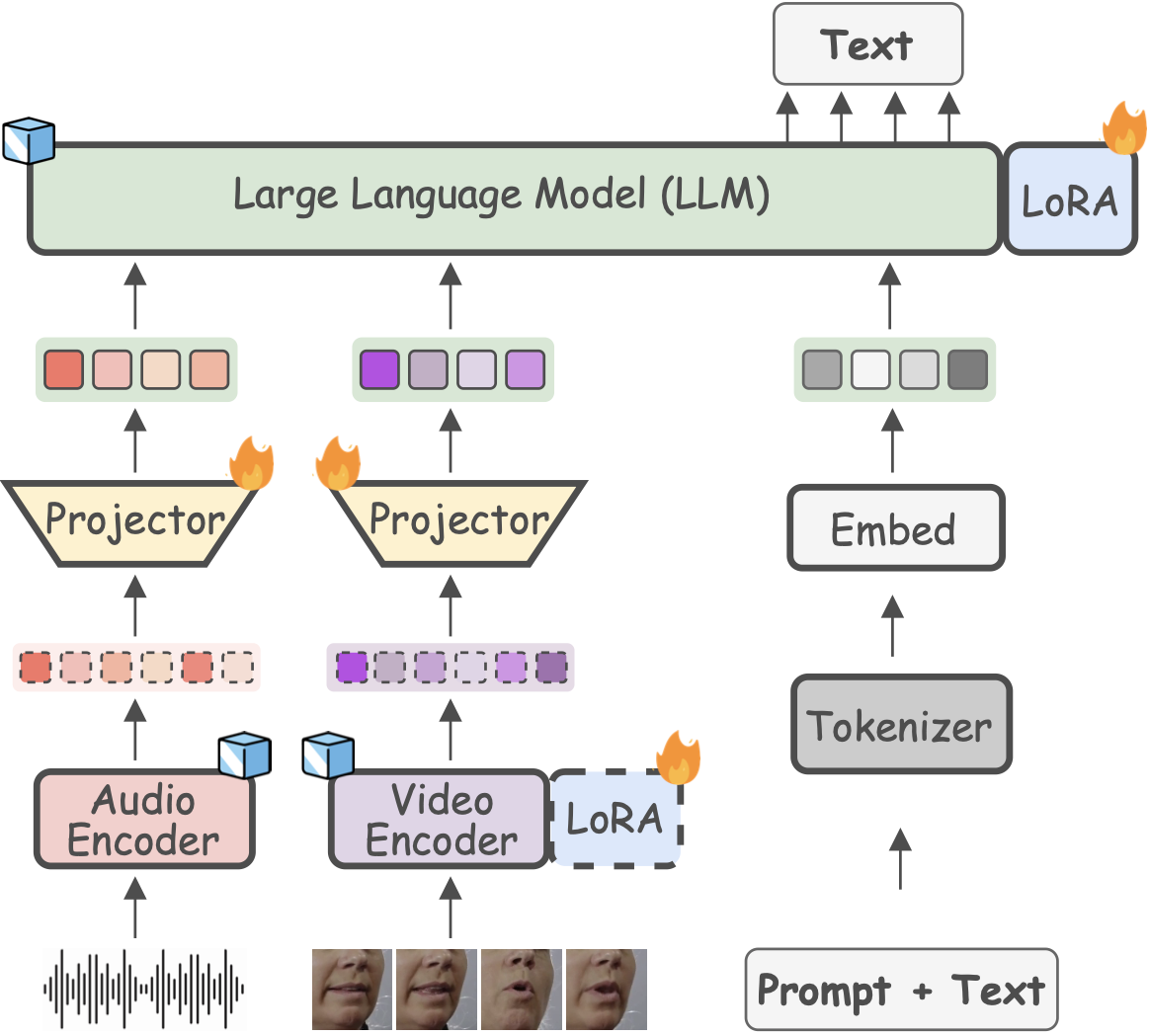
U. Cappellazzo, M. Kim, S. Petridis, D. Falavigna, A. Brutti
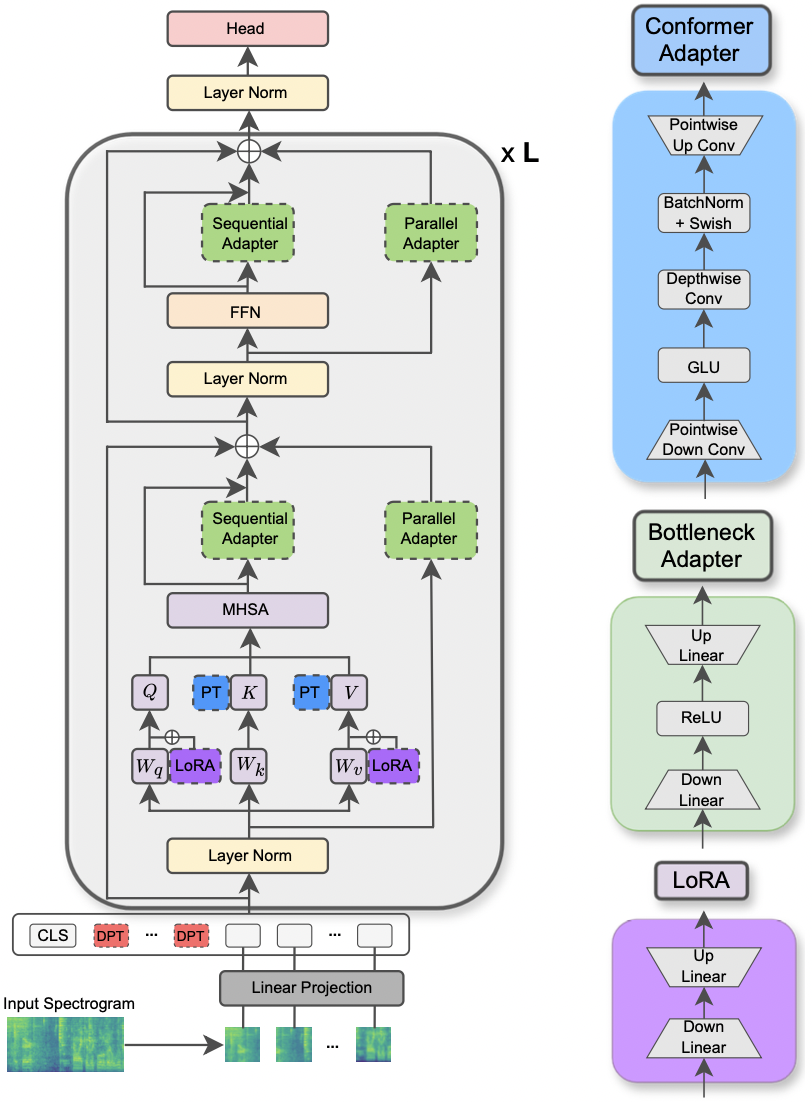
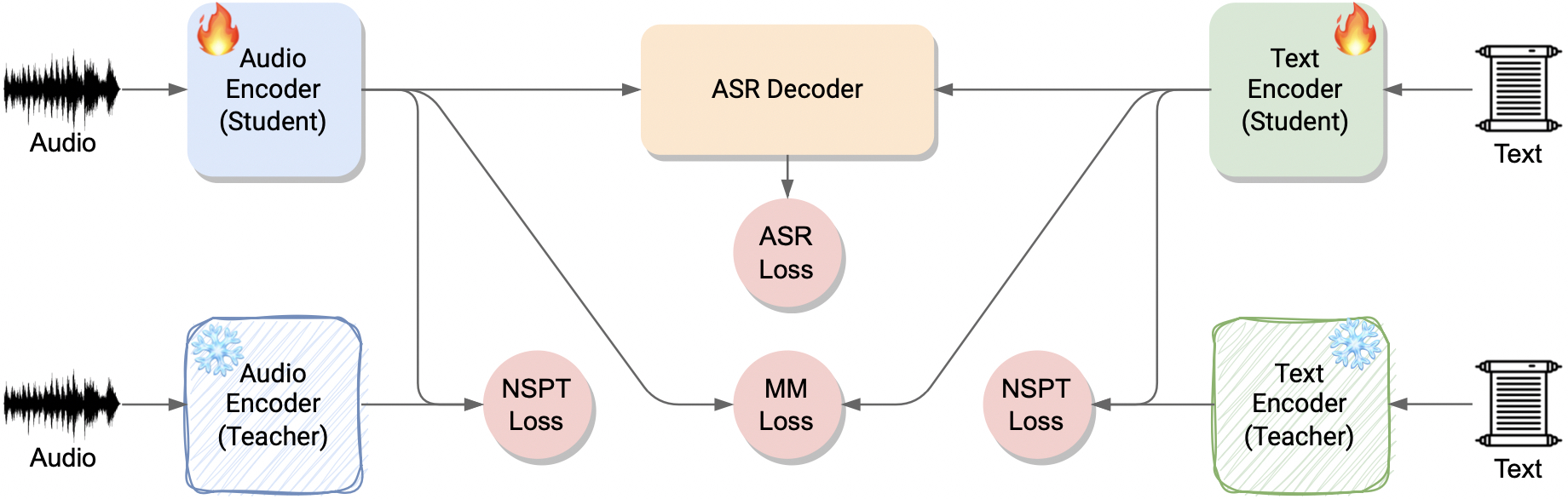
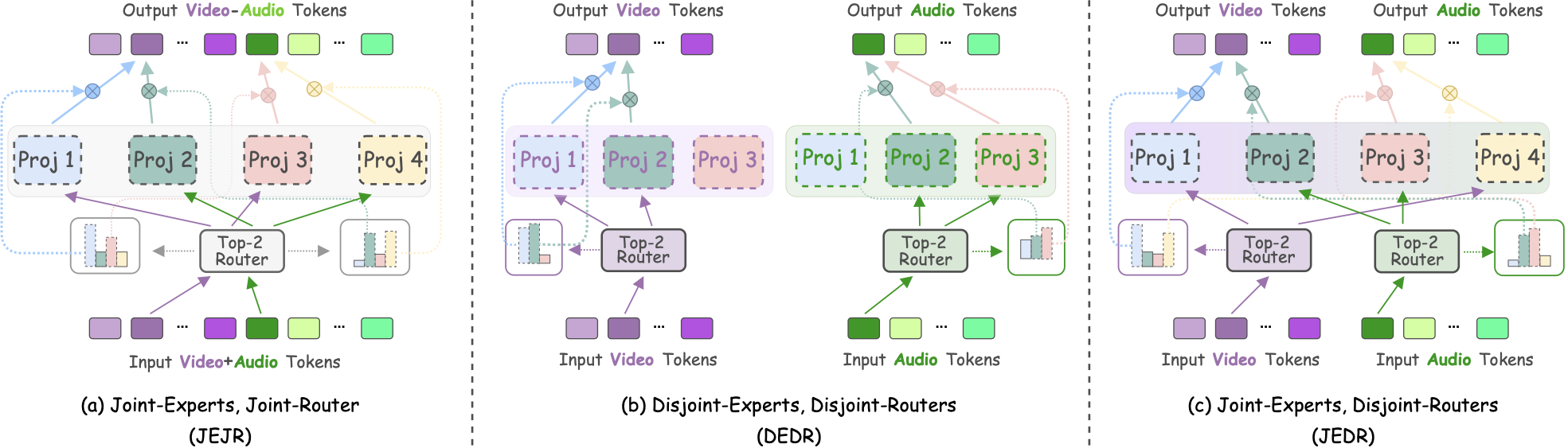
U. Cappellazzo, E. Fini, M. Yang, D. Falavigna, A. Brutti, B. Raj
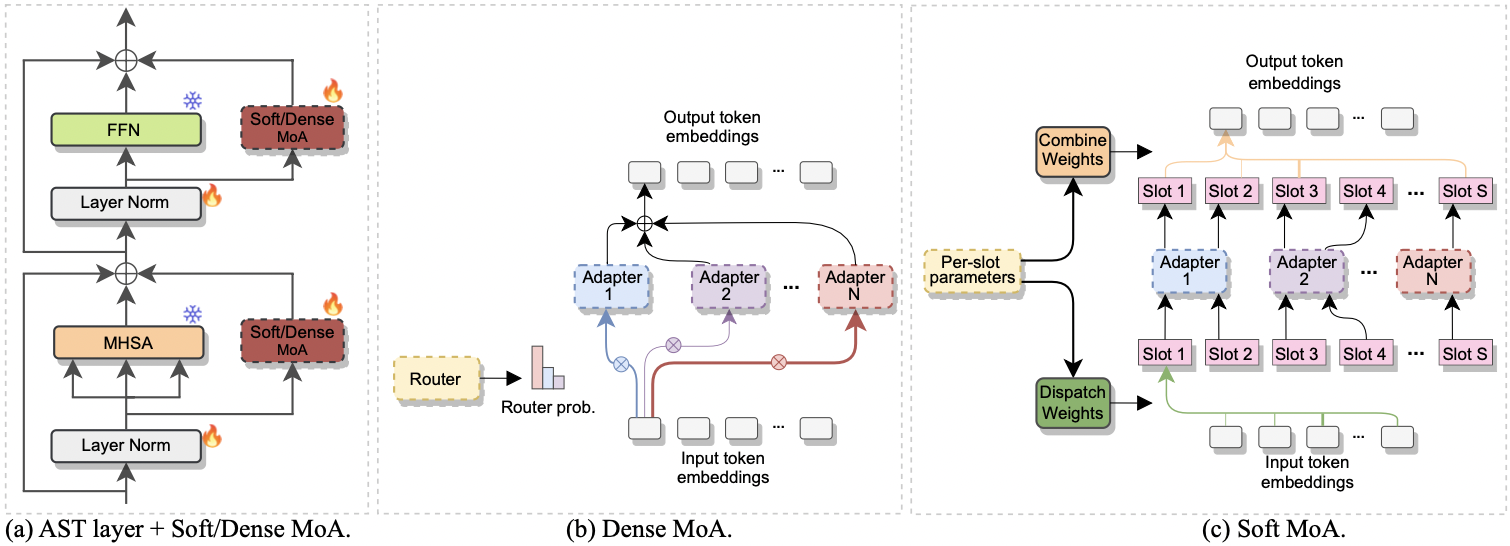
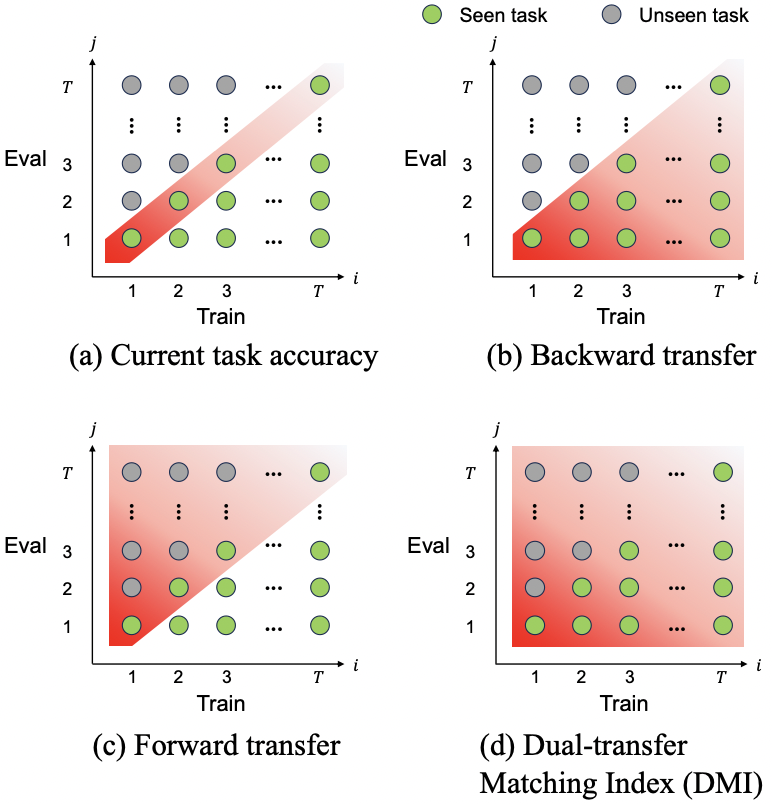
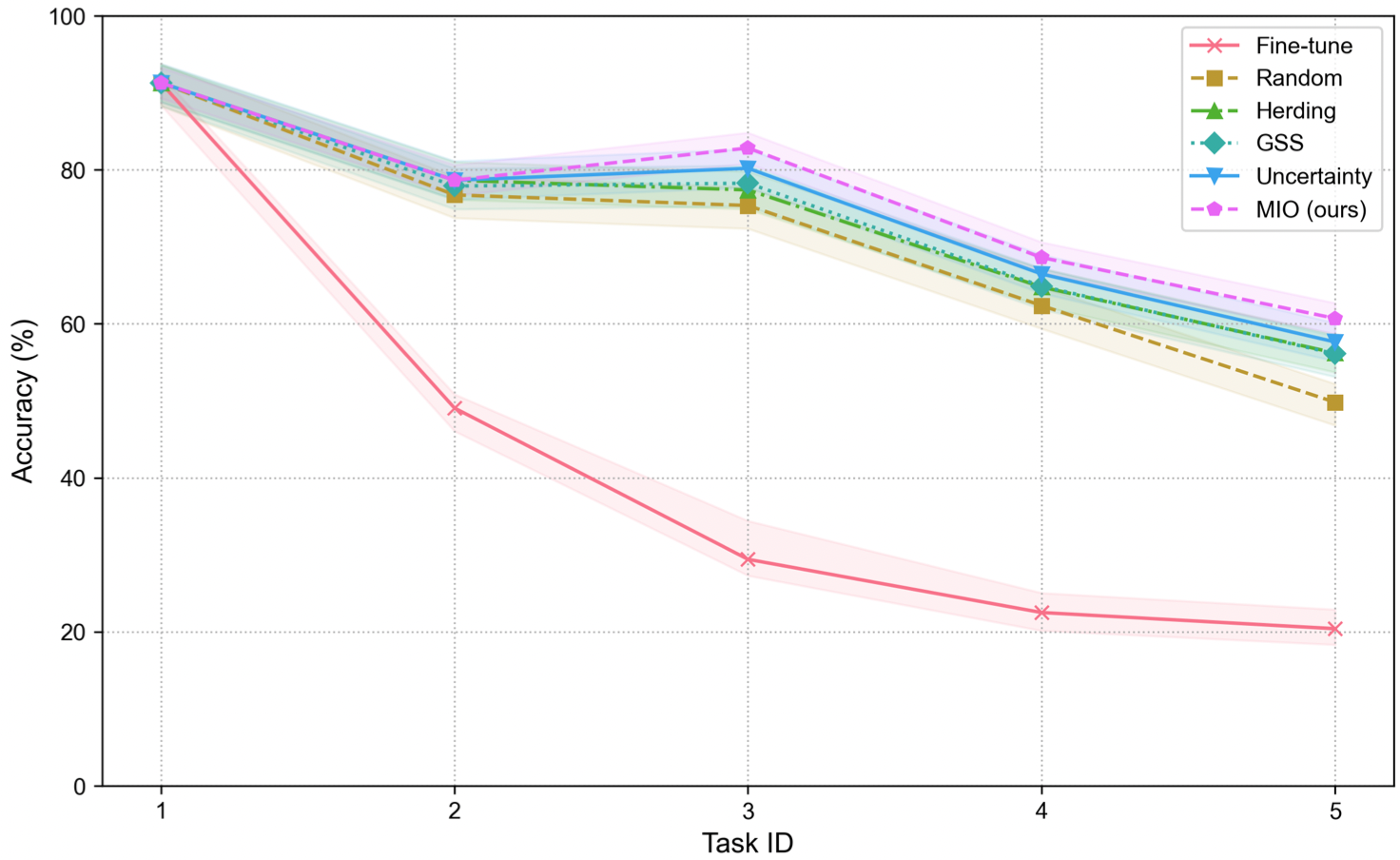
M. Yang, X. Li, U. Cappellazzo, S. Watanabe, B. Raj
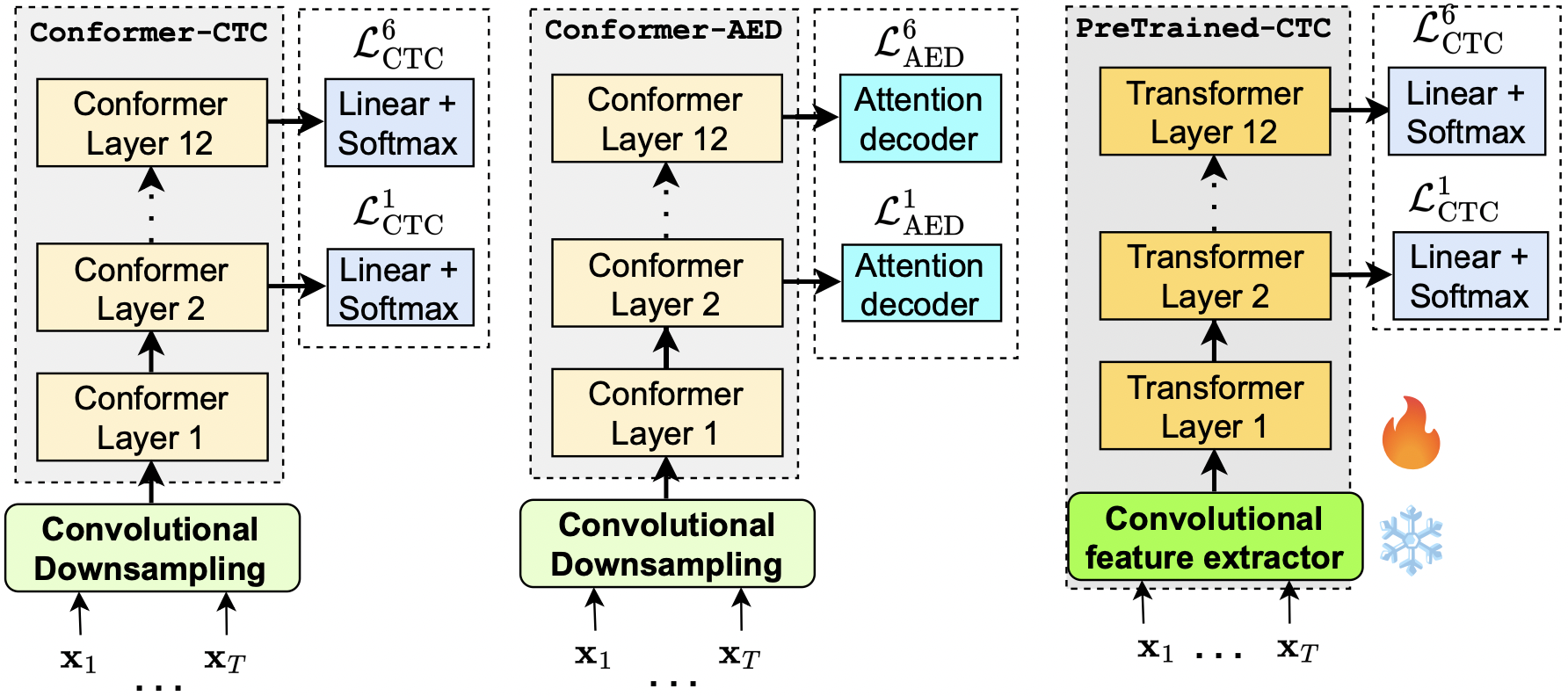
M. Yang, U. Cappellazzo, X. Li, S. Watanabe, B. Raj
Always happy to discuss audio & speech representation learning, multimodal LLMs, or collaborations. Reach me at umbertocappellazzo [at] gmail [dot] com.